Зачем он нужен?
Интерфейс МЭШ заточен под управление тыками мыши, причём все элементы управления в разных местах (и эти места ещё отличаются для разных режимов / размеров списка учащихся / количества уроков / темы урока и пр.). Каждое действие требует множества тыков в разные точки окна браузера.
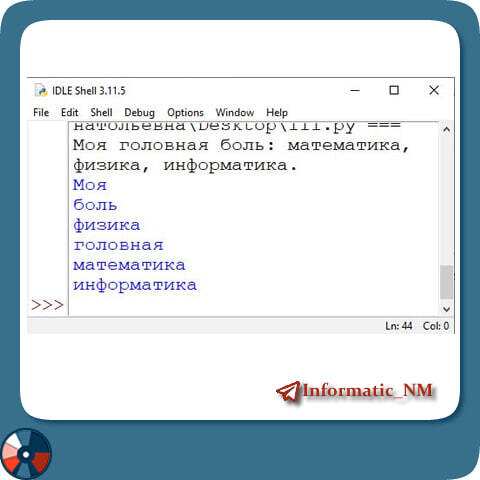
Гораздо проще набирать команды текстом, например:
«дз» — вставить текст ДЗ из буфера обмена в поле ввода уже открытого урока;
«иванов 5» — поставить указанную оценку выбранному ученику в уже открытом журнале;
«вт 3 у» — открыть журнал на вкладке «Урок» для третьего урока во вторник — из открытого расписания.
Мой скрипт предоставляет такую возможность. В силу особенностей интерфейса системы, он не универсален и требует некоторой настройки для каждого действия. Зато даёт как увеличение скорости работы, так и уменьшение урона здоровью, которое мы — преподаватели — получаем из-за значительного напряжения глаз и общей нервозности от множества кликов, когда каждый нужный элемент необходимо «поймать» мышью.
Скрипт никак не взаимодействует с базами данных или содержимым страницы — это простое управление мышью.
Скрипт я делала для себя. Но буду рада, если он пригодится и вам, коллеги.
Тестировалось в Яндекс-браузере на группах до 22 человек и максимальном количестве уроков в день — 6 (не считая «окон», которые в расписании не отображаются).
ИНСТРУКЦИЯ
Запускаем МЭШ в Яндекс-браузере.
Страница журнала должна быть открыта в масштабе 90%. Изменение масштаба отображения: [Ctrl]+[+] и [Ctrl]+[-].
Начинаем работу со страницы расписания.
► Открываем страницу урока в заданном режиме: урок / журнал
Команда:
день номер у/ж <строк>
где день = пн / вт / ср / чт / пт
номер = 1.6
<строк> (необязательный) = количество строк в теме урока (положение кнопки открытия зависит от длины строки темы)
Например:
вт 3 у
пт 6 ж 4
Тонкости:
• Я не знаю, как ведёт себя журнал, если уроков в вашем расписании больше шести в день без учёта «окон». У меня уроков по семь, но с окном — клеточек в расписании шесть. И они как раз занимают все пространство окна сверху донизу.
При более шести плашек уроков, наверное, либо требуется прокрутка, либо элементы разъезжаются (плашки уменьшаются). В обоих случаях скрипт использовать не получится или требуется подгонка координат.
► Ставим метку «Без домашнего задания» при открытой вкладке «Урок»
Команда:
бдз
► Копируем описание домашнего задания из буфера обмена в поле конкретного урока
Команда:
дз
Текст домашнего задания должен быть заранее скопирован в буфер обмена (например, через [Ctrl]+[C] или меню Правка → Копировать)
► Переходим в режим выставления оценок
Команда:
оценки положение группа
где положение = п / л — к какому краю сетки прижата колонка, куда будут выставляться оценки;
группа = название группы как в файле students.dat
Например:
оценки п 9а1
оценки л 10б
Предварительно:
• МЭШ должен быть открыт в режиме журнала на выбранном уроке
• Колонка оценок должна быть прижата к левому или правому краю сетки (см. скриншот)
Я не знаю, как это будет работать в начале года для нескольких уроков. Первый очевидно будет автоматически прижат к левому краю, а вот можно ли подвинуть влево второй-третий и т. д., пока не накопится целая страница колонок — надо будет проверять в следующем году.
• В журнале должен быть выбран «Расширенный режим», чтобы окошко выставления оценки распахивалось сверху донизу окна браузера (см. скриншот), иначе это окошко всегда оказывается в разных (непредсказуемых) местах, и скрипт не сможет «поймать» кнопку оценки
• Файл students.dat должен быть заполнен (см. ниже формат файла)
• Для колонки должен быть заранее выбран тип работы (кроме «Домашнего задания», см. дальше).
• Темой урока не может быть «Повторение», т. к. в этом случае требуется выбирать тему для каждой оценки.
► Выставляем оценку ученику в режиме выставления оценок
Команда:
иванов 5 <2>
где иванов = фамилия учащегося в любом регистре
5 = оценка 2.5
<2> (необязательный) — вторая оценка в той же клетке.
► Формат файла students.dat
На каждой строке — сведения об одном ученике.
группа|номер|фамилия
Например
9а1|1|Иванов
9а1|2|Петров
10б|1|Сидоров
и т.д.
Необязательно вся группа подряд.
Номер должен соответствовать номеру учащегося в списке группы — точно как в МЭШ на странице выставления оценок.
Тонкости:
• Для типа работы «Домашнее задание» добавили дополнительные элементы интерфейса, и теперь кнопки оценок находятся не там, где для других типов.
Я решаю эту проблему так:
— выбираю другой тип работы;
— выставляю оценки;
— меняю тип работы на «домашнее задание»
• Для урока повторения приходится выбирать тему для каждой оценки. Скрипт поставит оценку, но без темы сохранить её не сможет.
Прикреплённые файлы:
► txtgui4mash.exe — скомпилированная автономная программа, ничего не требует, кроме Windows. Запакована в zip-архив, т. к. 12 Mb размером (потому что Python).
► txtgui4mash.py — исходный код программы (если вы боитесь exe-шников или хотите изменить скрипт под свои нужды). Для работы нужно установить библиотеку pyautogui.
► students.dat — пример файла с данными учеников. Должен находиться в той же папке, что и txtgui4mash.exe (или в папке Python-проекта). Кодировка: ANSI (Windows-1251).