Разработка транспортных систем. Ч2 (маршруты, рейсы, рассписания)
Первая часть тут.
Маршруты
Следующий после остановок файл который разумно изучить это маршруты (routes.txt), так он выглядит:

так выглядит первый маршрут:
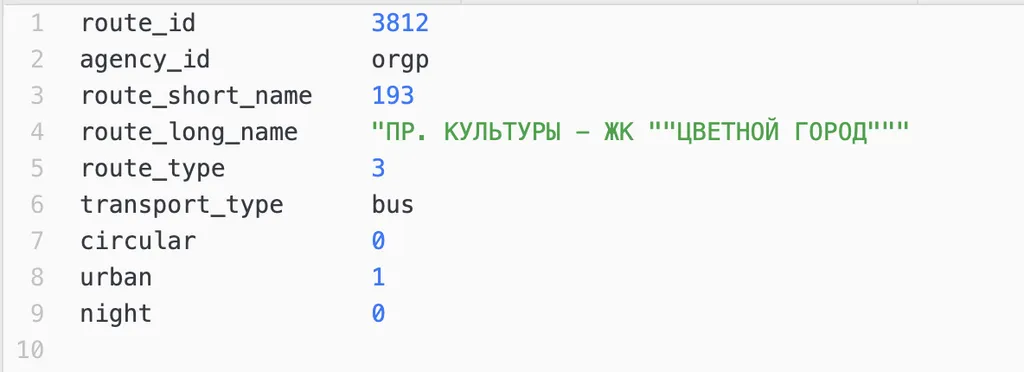
вопросы к нему возникают стандартные, как по остановкам:
- Сколько всего маршрутов?
- Сколько всего уникальных route_id?
- Сколько всего уникальных agency_id и что это такое?
- Сколько всего уникальных route_short_name и что регистром?
- Сколько всего уникальных route_long_name и что регистром?
- route_type что это и какие значения принимает?
- transport_type какие значения принимает и как часто?
- circular какие значения принимает и как часто?
- urban какие значения принимает и как часто?
- night какие значения принимает и как часто?
Читаем маршруты из файла в память:

и отвечаем на первые четыре вопроса:
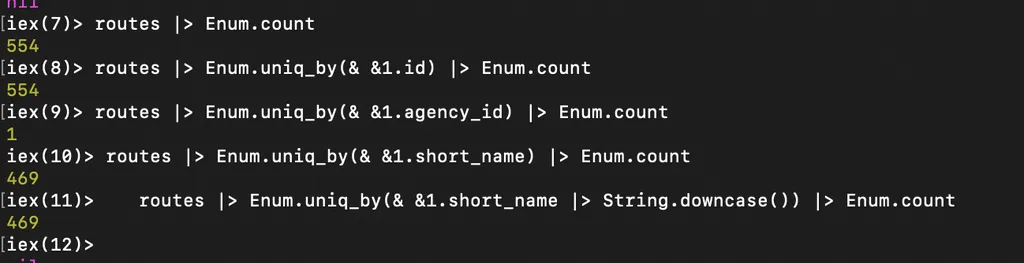
1 – маршрутов всего 554
2 – route_id везде уникален, а значит может играть роль идентификатора в рамках фида
3 – agency_id везде одинаковый (orgp), а значит это мусор
4 – route_short_name не везде уникален (469 уникальных из 554), приведение к регистру ничего не меняет
после ответа на четвертый вопрос возникает доп вопрос о распределении дублей, отвечаем:

видно что полностью уникальных route_short_name 408, еще 37 дублируются парами и еще 24 дублируются тройками. Из предыдущего разбора остановок, мы помним что они бывают автобусные, троллейбусные и трамвайные, тут возникает гипотеза, что route_short_name, являсь номером маршрута может быть уникальным в рамках вида транспорта.
Сначала для каждого неуникального номера маршрута нужно получить объект с частотой видов транспорта:
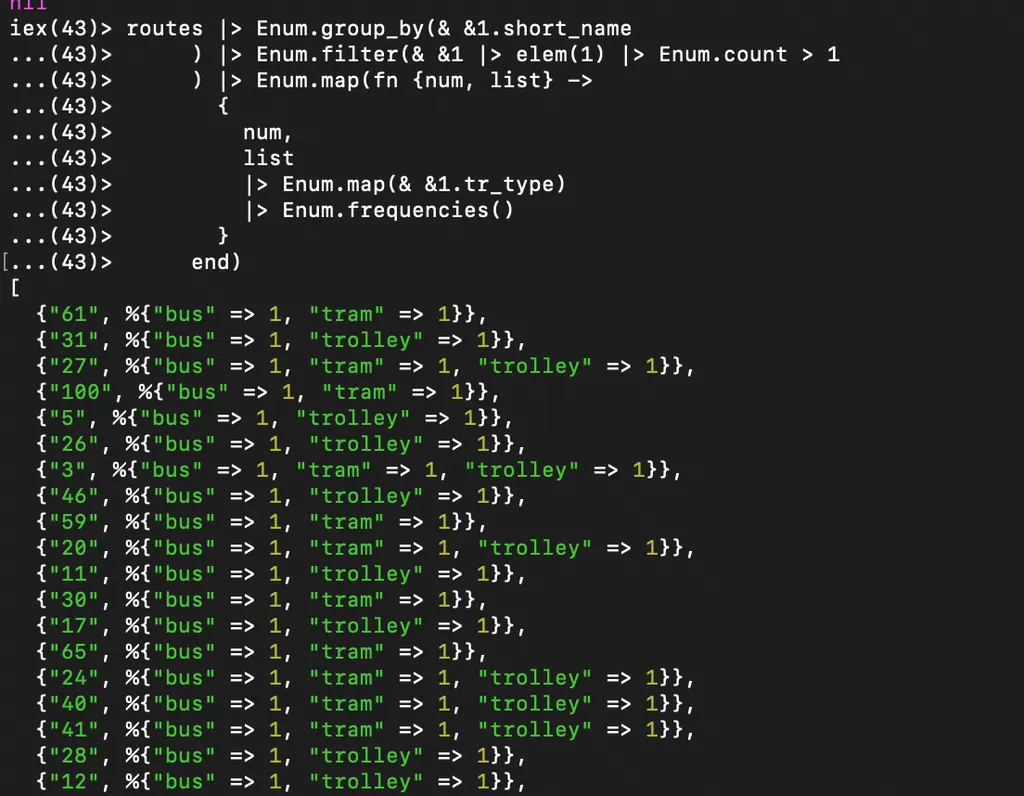
Теперь фильтруем те, в которых какой-нибудь вид транспорта встречается чаще чем один раз:

таких нет, значит route_short_name действительно уникален в рамках вида транспорта.
Отвечаем на оставшиеся шесть вопросов:

5 – route_long_name не везде уникален (526 уникальных из 554), приведение к регистру создает еще один дубль (становиться 525 уникальных из 554)
проверив на уникальность в рамках вида транспорта (не вставляю картинку) обнаруживаем что полное наименование маршрута не уникально в рамках вида транспорта, т.е есть например:
- три автобусных маршрута "Ж.-Д. СТАНЦИЯ НОВЫЙ ПЕТЕРГОФ - Ж.-Д. СТАНЦИЯ СТАРЫЙ ПЕТЕРГОФ" с номерами 351Б, 351А и 353
- два автобусных маршрута "Г. СЕСТРОРЕЦК, КУРОРТНАЯ УЛ. - Ж.-Д. ПЛАТФОРМА ПЕСОЧНАЯ" с номерами "315." и "315" [! что говорит что из номеров еще нужно убирать знаки препинания]
еще тут возникает желание проверить не является ли название маршрута склейкой названий первой и последней остановки, но мы пока не видели трассировки маршрутов по остановкам.
6, 7 – route_type и transport_type судя по всем оба отвечают за вид транспорта, причем transport_type более точный, т.к. он показывает все три вида, а route_type отделяет трамвайные от нетрамвайных
значит route_type это мусор (зная transport_type всегда можно получить route_type), автобусных маршрутов – 462, троллейбусных – 47, трамвайных – 45. Интересно что трамвайных маршрутов всего на два меньше троллейбусных, хотя остановок было меньше на 457. Пока выглядит как аномалия, но связь между остановками и маршрутами будет дальше.
8 – есть 30 маршрутов которые является circular, видимо круговые, т.е. начинаеются и заканчиваются в одной остановке. Они все автобусные и у всех наименовение либо "X - X", либо "X - X (Кольцевой)"
9 – есть 53 не urban маршрутов и 501 urban, все не urban автобусные.
10 – есть 554 маршрута не night (night везде 0), а значит это мусорный атрибут.
Рейсы
Рейсы (trips.txt) выглядят так:

Тут много ссылкок на другие файлы:
- route_id – ссылка на файл routes.txt поле route_id
- service_id – ссылка на файлы calendar_dates.txt и calendar.txt поле service_id
- trip_id – не ссылка на другой файл, потенциально идентификатор внутри файла
- direction_id – не ссылка на другой файл, видимо направление маршрута (0 прямо, 1 - обратно или наоборот)
- shape_id – ссылка на файл shapes.txt поле shape_id
Помимо стандартных вопросов:
- Сколько всего рейсов?
- Сколько уникальных trip_id?
- какие значения принимает direction_id?
Возникают кросс-файловые вопросы:
- Все ли route_id из trips есть в routes? (т.е. нет ли рейса ссылающегося на несуществующий маршрут?)
- Все ли route_id из routes есть в trips? (т.е. нет ли маршрута для которого нет ни одного рейса?)
- те же вопросы к service_id и shape_id (кроме третьего вопроса)
- к shape_id есть доп вопрос, по крайней мере в начале файла shape_id выглядят как префикс "track-" + число. При хранении и обработке данных числа всегда эффективнее строк (а целые числа эффективнее десятичных), например число 32000 при использовании типа smallint в postgres будет весить два байта, а строка "32000" – пять байт. Дак вот вопрос к shape_id это нельзя ли его хранить как число, избавившись от перфикса.
- Сколько в среднем рейсов на маршрут? (максимум, минимум, медиана, квартильный размах?)
Сначала стандартно читаем рейсы в память:

тут стоит учесть что файл маршрутов весил 64Кб, а файл рейсов 4.5Мб (в 72 раза больше). Если засечь время записи в память (чтение +парсинг) то получим примерно 500мс для рейсов, и 10 мс для маршрутов. Самый большой файл (stoptimes.txt –185Мб) нас ждет впереди, но уже сейчас можно кое-что улучшить. Например написать код для чтения рейсов как функцию внутри модуля, скомпилировать его, и вызывать чтение через эту функцию:

так время выполнения на моем компе вместо ~500мс занимает ~100мс, в пять раз быстрее.
Стандартно узнаем что рейсов 124 915, и все trip_id уникальны. Поле direction_id принимает значение 0 – 62 539 раз, а значение 1 – 62 376 раз. К direction_id мы еще вернемся когда разберемся со связью рейсов и остальных файлов.
Кросс файловые вопросы, маршруты
Чтобы эффективно проверять наличие маршрута или рейса по идентификатору, нужно сложить их в объект ключ-значение:
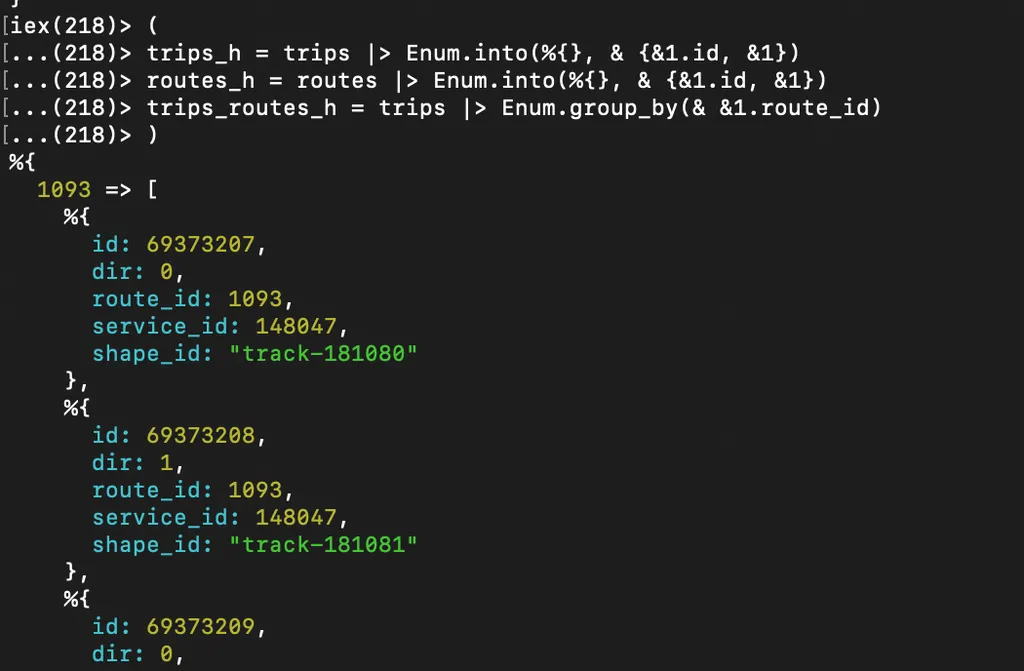
Постфикс _h я использую чтобы понимать что переменная является объектом ключ-значение, а не например списком.
Теперь можно за константное время по ключу быстро либо получать маршрут, либо получать nil если маршрута с таким ключом нет:
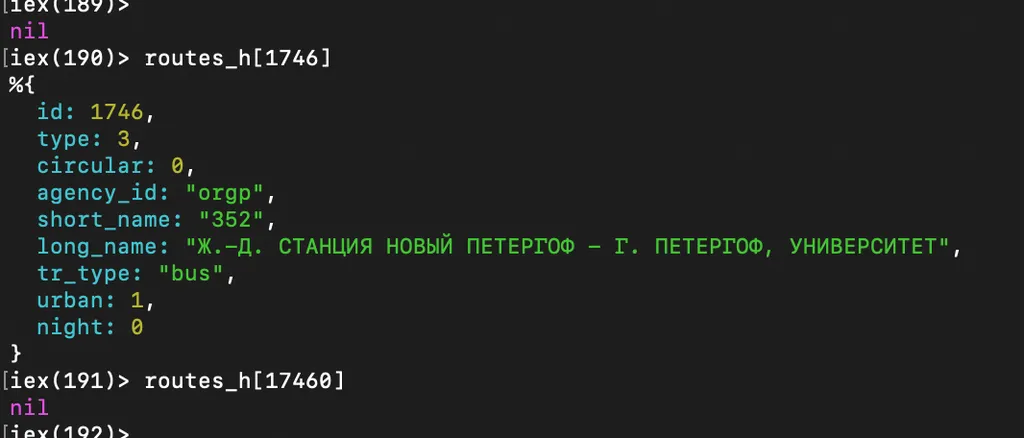
Стандартная ошибка стажера (даже того который знает про вычислительную сложность алгоритмов, и про структуры данных), причем на любом языке, тут не важен конкретно эликсир, это искать маршрут путем поиска в списке, типа так:

Для того чтобы проверить так наличие маршрута для каждого рейса, понадобится прикидочно 120к рейсов * 500 маршрутов = 60 млн операций, вместо 120к операций, разница в 2 порядка.
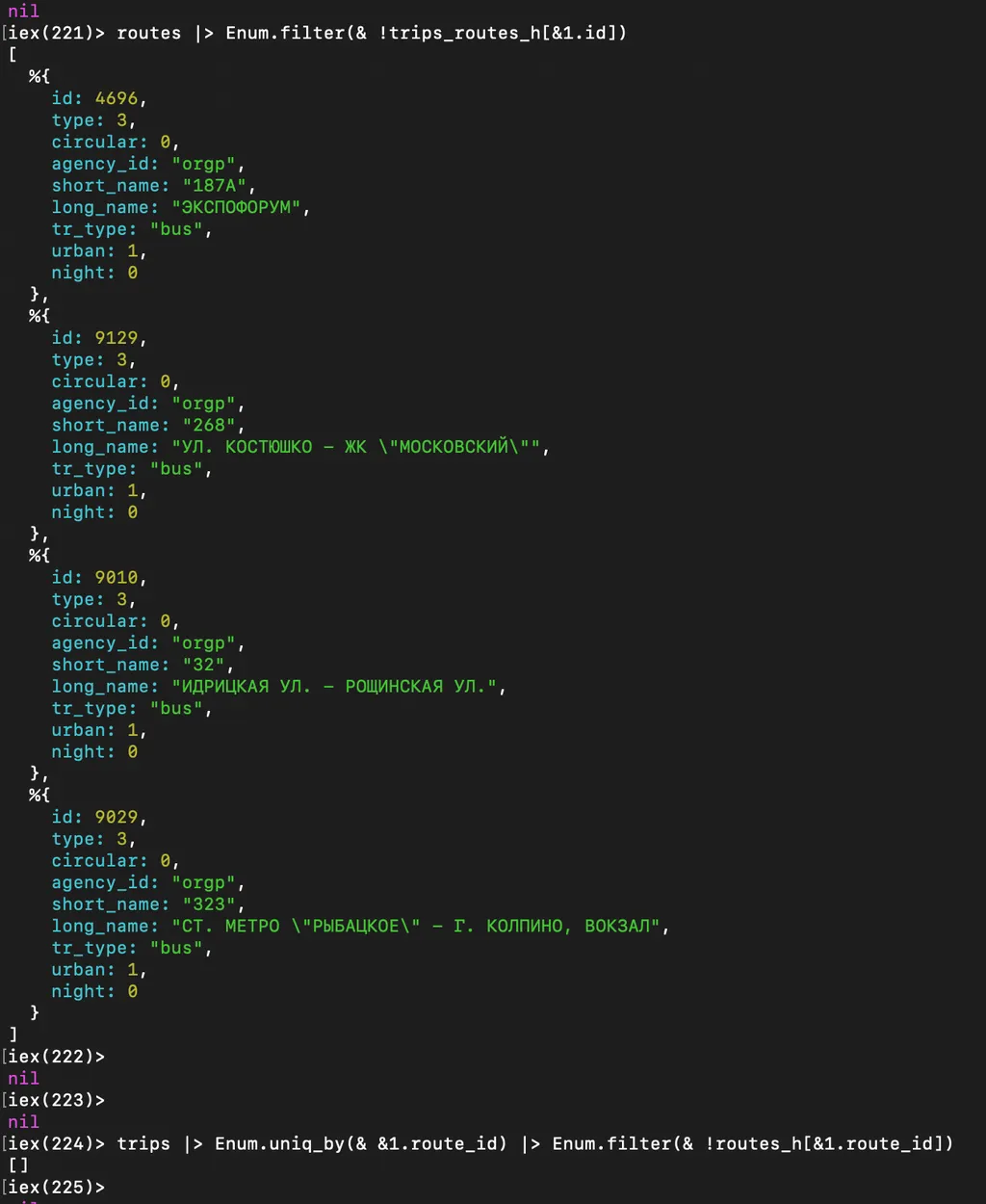
Маршрутов, для которых отсутствуют рейсы всего четыре, а рейсов без маршрута нет совсем:
Кросс файловые вопросы, календари
файл calendar.txt выглядит так:
а calendar_dates.txt так:

Отсюда можно узнать что exception_type в calendar_dates это возможность поменять для конкретной даты один service_id на другой. Дата фида (5 июля 2025) в этом файле не встречается, поэтому файл не представляет интереса.
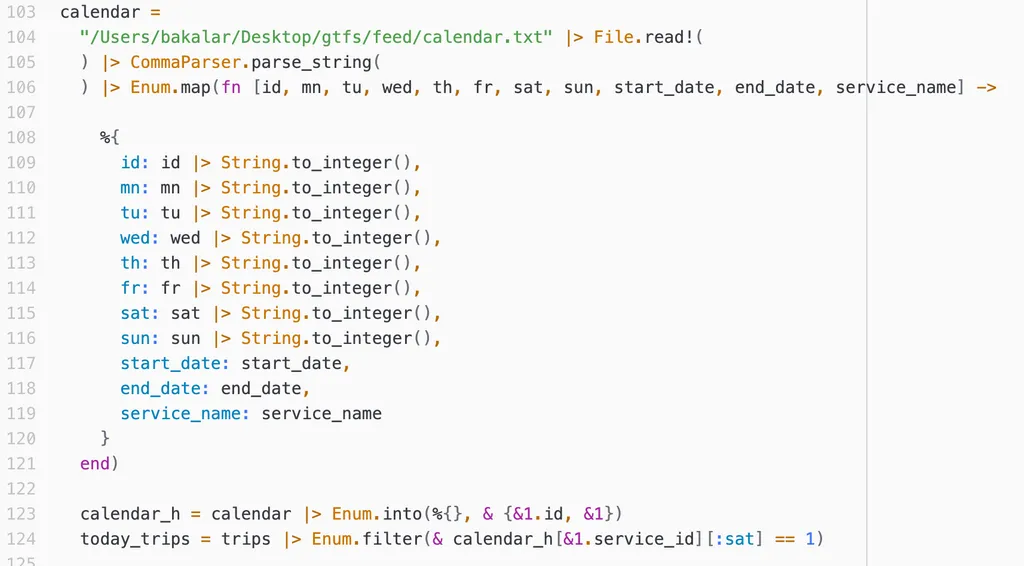
5 июля 2025 – была суббота, соответственно из файла calendar.txt актуальными являются только те service_id, у которых атрибут saturday = 1. Фильтруем рейсы:
Рейсов актуальных на дату фида остается 57 138 из начальных 124 915, уникальных route_id среди них - 532. Количество рейсов на маршрут:
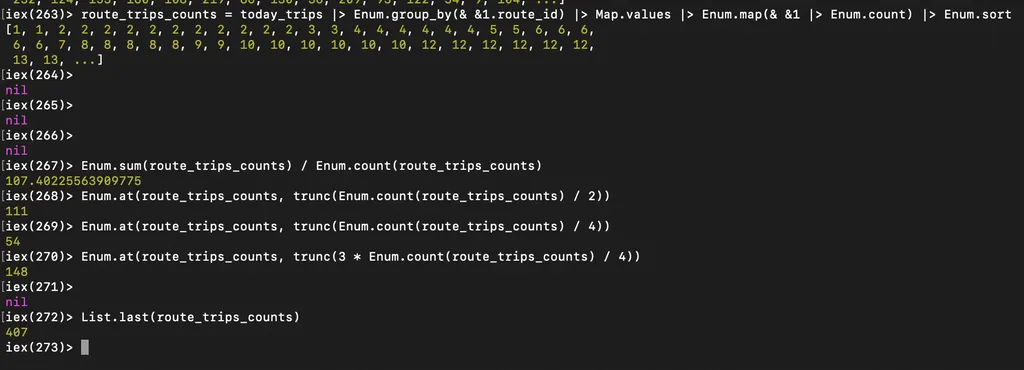
В среднем – 107 рейсов на маршрут, медиана – 111, половина маршрутов имеет от 54 до 148 рейсов (квартильный размах), максимум у какого-то маршрута 407 рейсов в день (примерно каждые шесть минут).
Кросс файловые вопросы, shapes
Сделать shape_id числом, просто убрав приставку "track-" вроде бы ничто не мешает, с учетом нюанса что некотоые рейсы имеют пустой shape_id:

число-постфикс в shape_id находится в диапазоне от 100 000 до 200 000.
Есть 11 shape_id в рейсах, отсутствующих в shapes.txt, 1 852 рейса имеют какой-то из этих битых идентификаторов:

Итоги
Осталось изучить файлы stoptimes и shapes, после этого, зная всю специфику данных, можно будет запроектировать требования к будущей системе, и исходя из них сформировать структуру БД, и написать импорт из фида в БД.