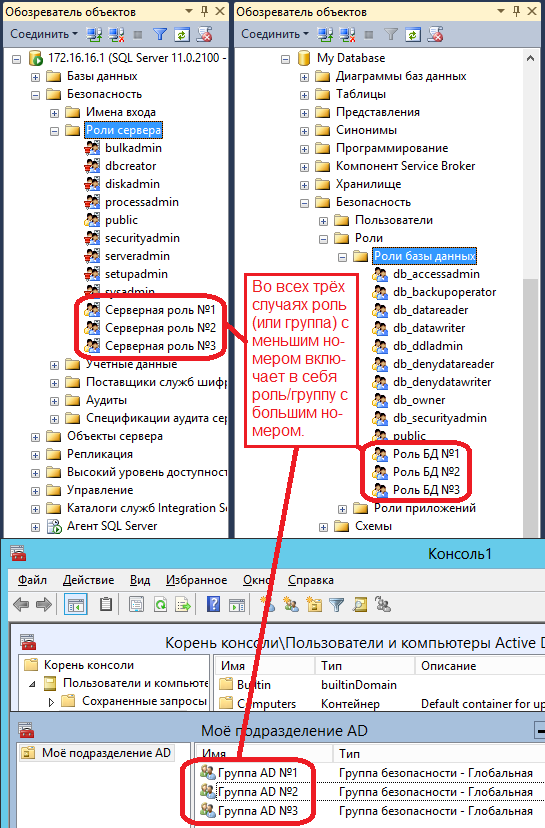
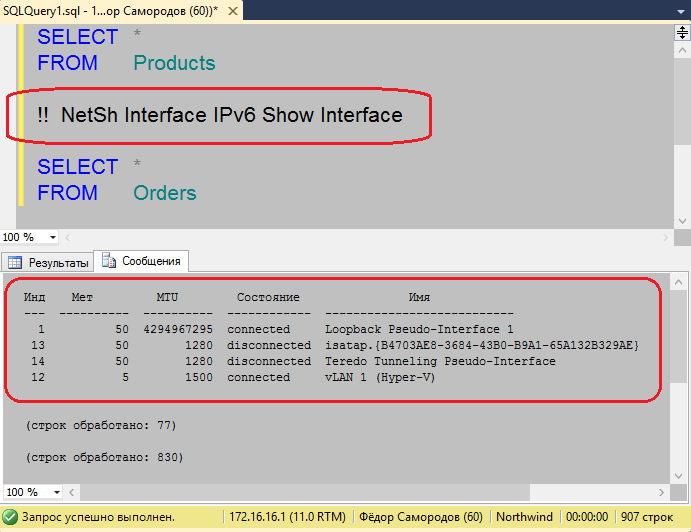
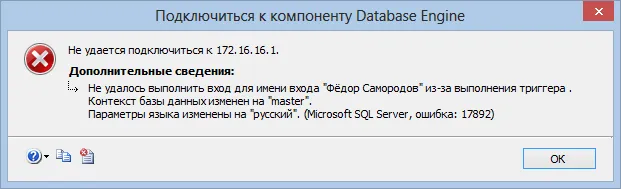
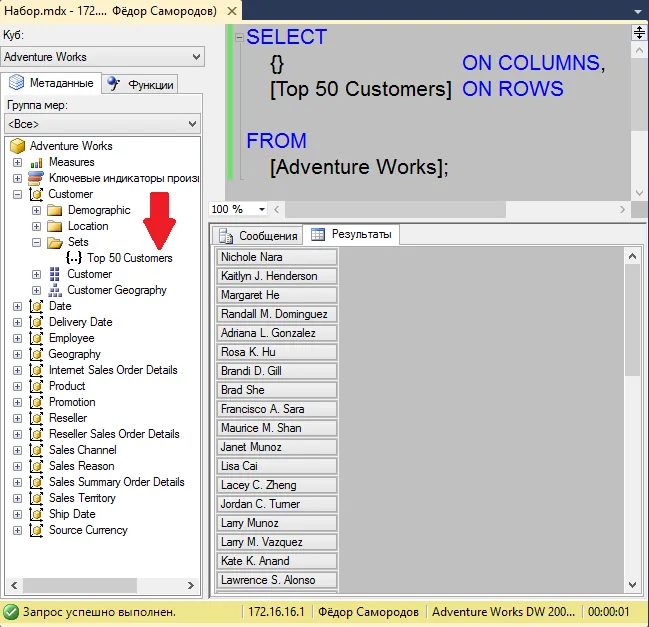
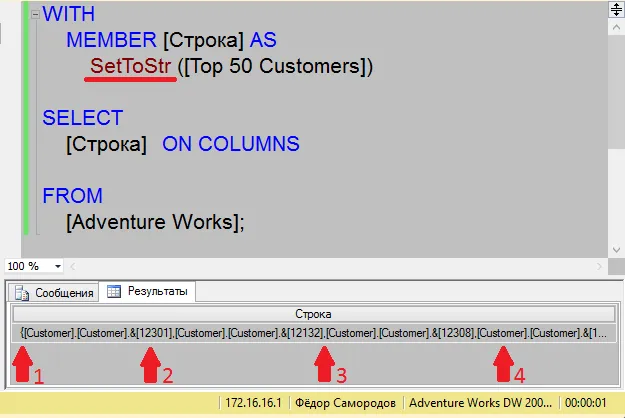
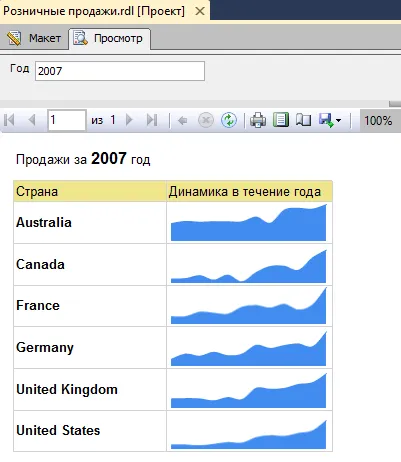
Если ваш запрос выполняется подозрительно долго или выглядит зависшим, возможно, он попал в блокировку. Можно просто подождать в надежде, что тот, кто нас заблокировал, вскоре закончит работу и отпустит блокировку… Но обычно хочется узнать, кто же нас заблокировал.
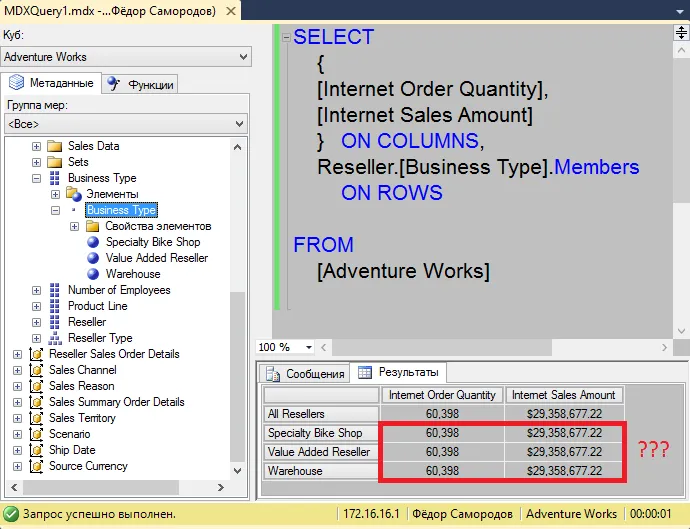
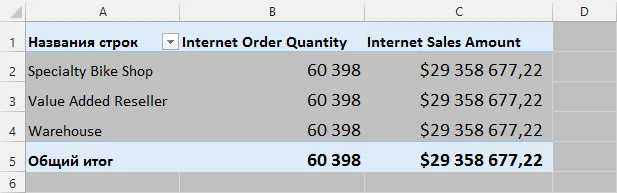
Разумеется, SQL Server отслеживает кто кого и почему блокирует. И у нас даже есть несколько инструментов, чтобы это увидеть. Самый простой способ — системное представление (DMV) sys.dm_Exec_Requests.
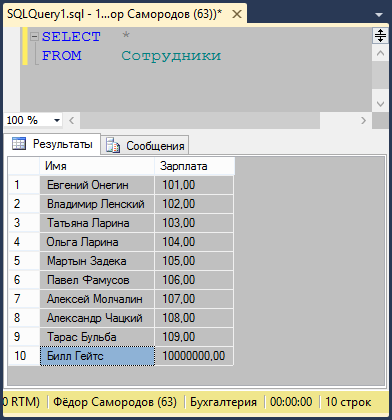
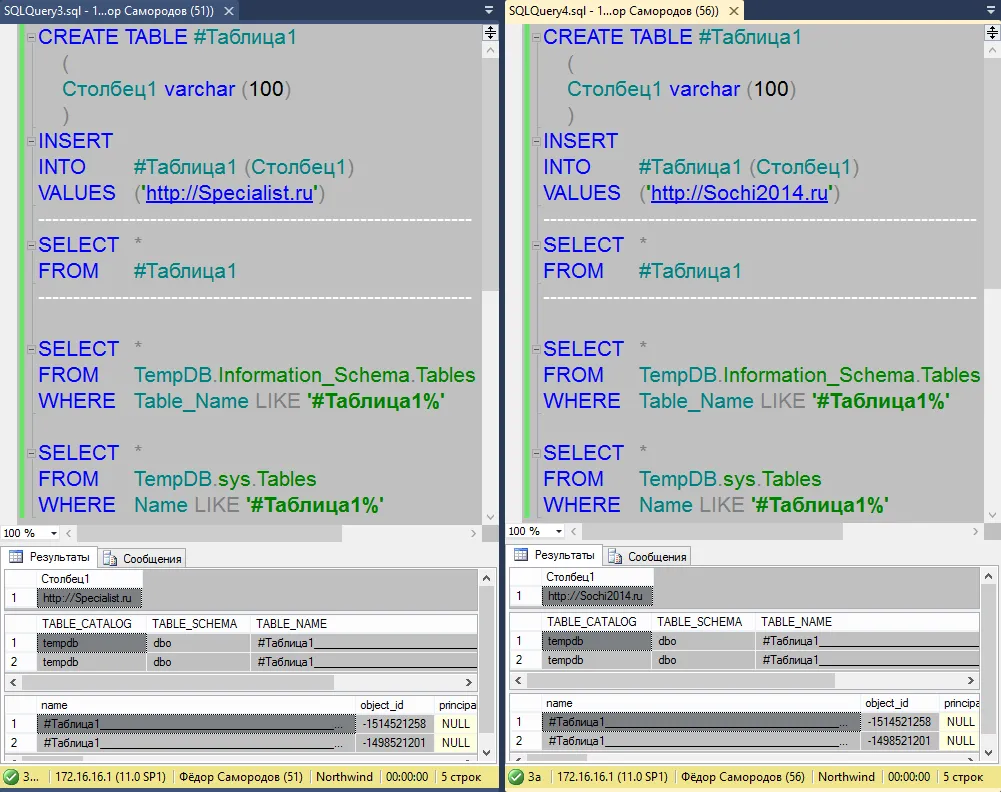
Сначала нужно узнать номер нашего процесса (сеанса). Этот номер можно узнать, заглянув в системную переменную @@SPID:
SELECT @@SPID
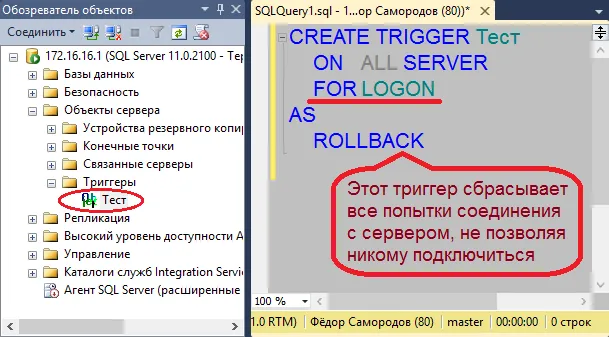
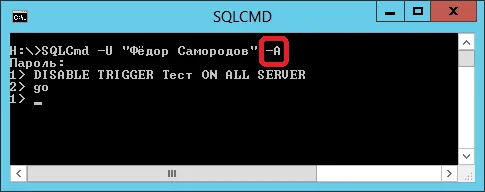
Правда, если запрос уже выполняется, то опросить эту переменную вы не сможете. Но обычно этот номер видно в клиентском приложении:

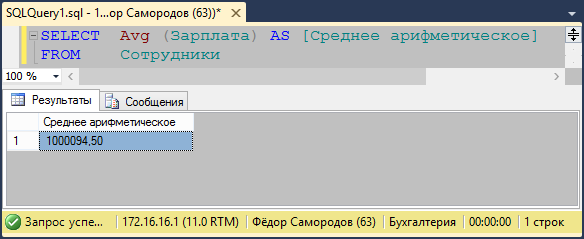
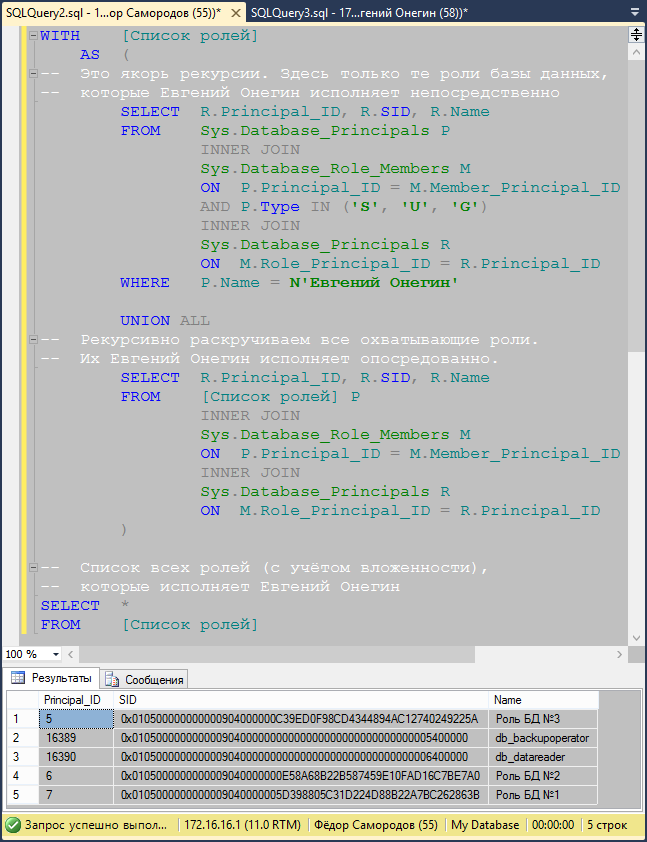
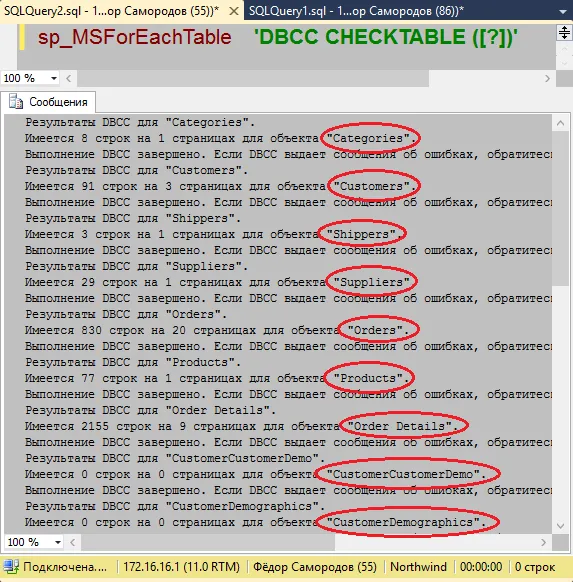
Теперь, зная номер нашего процесса, заглянем в sys.dm_Exec_Requests. В этом представлении уже содержится ответ на интересующий нас вопрос — столбец Blocking_Session_ID указывает на того, кто нас блокирует.
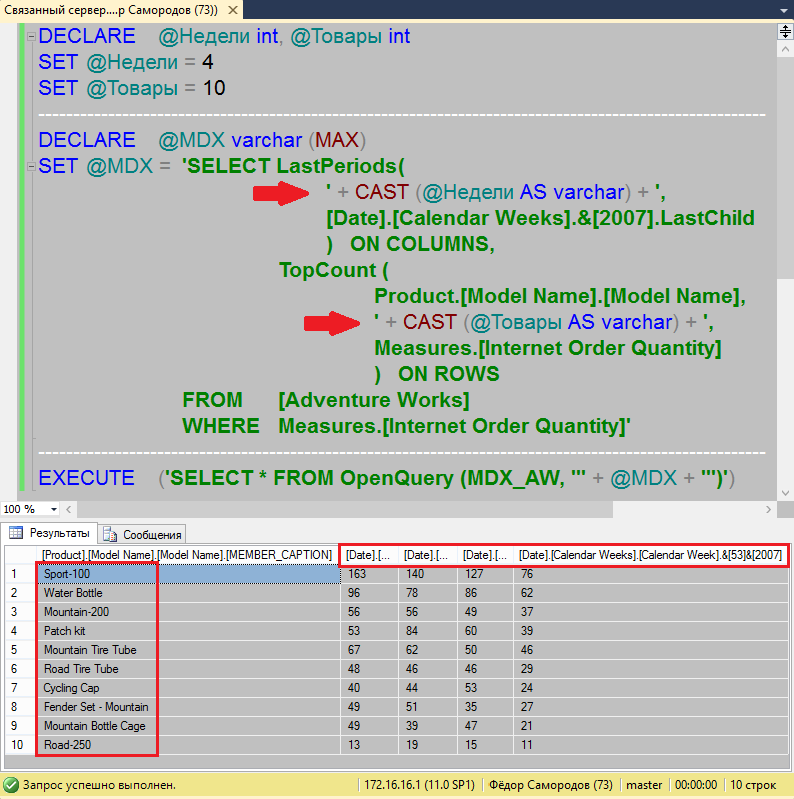
Теперь можем посмотреть на атрибуты процесса, который нам мешает. Наиболее информативно в этом плане представление sys.dm_Exec_Sessions. Из него вы узнаете кто, с какого клиентского компьютера и из какого приложения запустил блокирующий процесс.
Если ваш запрос выполняется подозрительно долго или выглядит зависшим, возможно, он попал в блокировку. Можно просто подождать в надежде, что тот, кто нас заблокировал, вскоре закончит работу и отпустит блокировку… Но обычно хочется узнать, кто же нас заблокировал.
Разумеется, SQL Server отслеживает кто кого и почему блокирует. И у нас даже есть несколько инструментов, чтобы это увидеть. Самый простой способ — системное представление (DMV) sys.dm_Exec_Requests.
Сначала нужно узнать номер нашего процесса (сеанса). Этот номер можно узнать, заглянув в системную переменную @@SPID:
SELECT @@SPID
Правда, если запрос уже выполняется, то опросить эту переменную вы не сможете. Но обычно этот номер видно в клиентском приложении:
Теперь, зная номер нашего процесса, заглянем в sys.dm_Exec_Requests. В этом представлении уже содержится ответ на интересующий нас вопрос — столбец Blocking_Session_ID указывает на того, кто нас блокирует.
Теперь можем посмотреть на атрибуты процесса, который нам мешает. Наиболее информативно в этом плане представление sys.dm_Exec_Sessions. Из него вы узнаете кто, с какого клиентского компьютера и из какого приложения запустил блокирующий процесс.