Минутка результатов локальных моделей

Последние пару недель ушли, кроме оторванных от ИИ бытовых вещей, уже на реальные рабочие эксперименты с локальными моделями.
Как писал в канале, к сожалению использование vLLM вместе с Ryzen 395 пока выглядит максимум как спортивная дисциплина. Всё работает, но вдвое медленнее чем под llama.cpp, а появление спекулятивного декодирования в виде MTP в последней сделало все остальные варианты запуска моделей малоинтересными на практике.
Параллельно стало окончательно понятно, что Qwen 3.6 в обоих своих вариантах (27B dense и 35B MoE) фактически уничтожил на сегодня потребность запуска любых других моделей локально. Нет, модели несколько лучше есть, но для нормальной работы им нужны уже серверные конфигурации, т. к. объема памяти в 128Гб просто перестает хватать, а кластерные истории на мини-ПК для таких моделей глубоко сомнительны из-за относительно низкого абсолютного уровня производительности.
Как итог, Qwen 3.6 наше все. Смотрим на тесты SWE-bench_Verified и SWE-bench_Pro на Hugging Face:
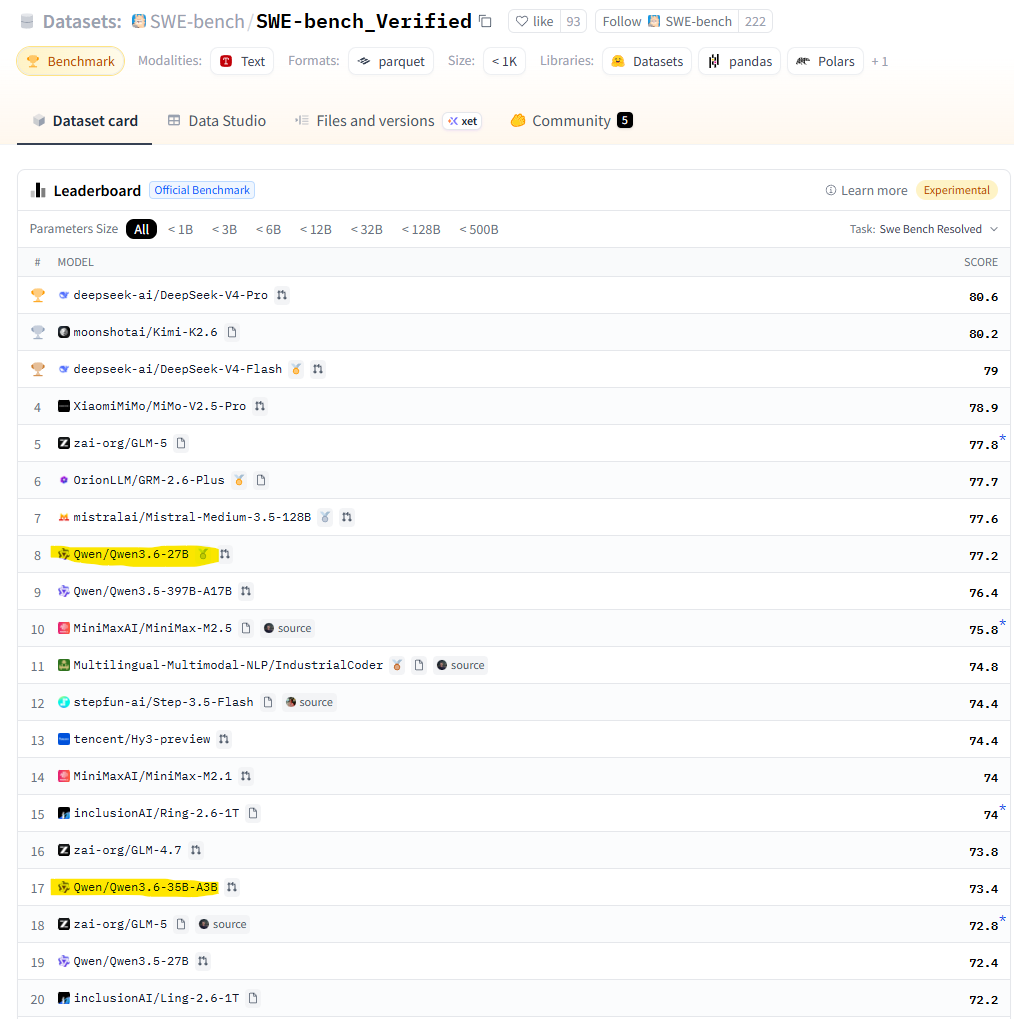
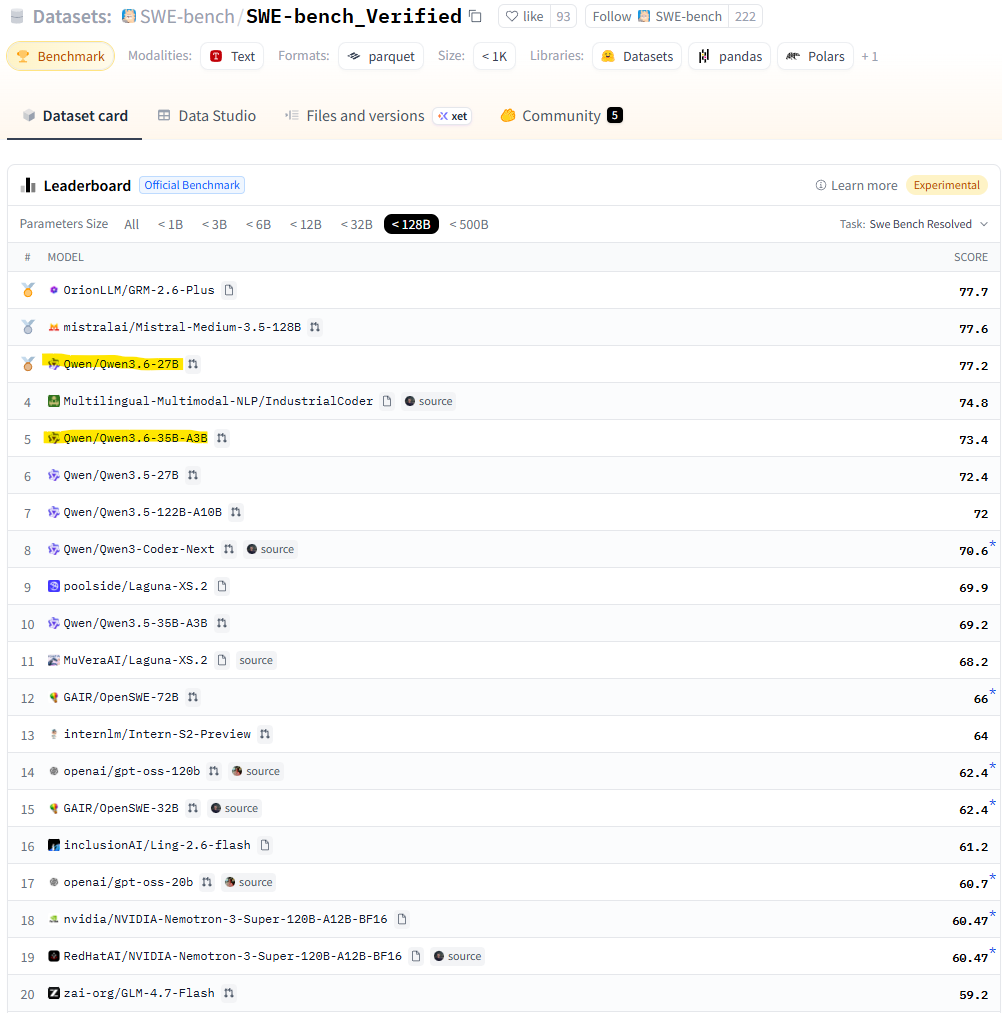
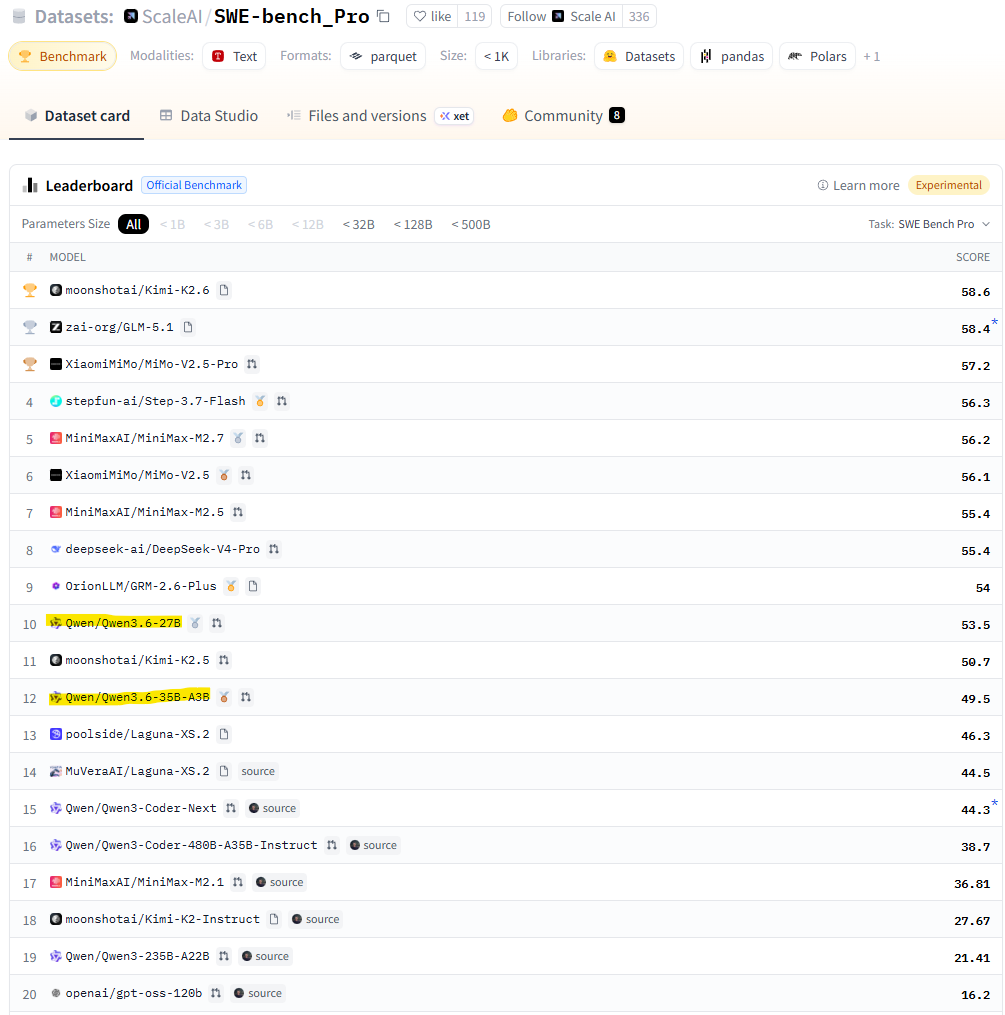
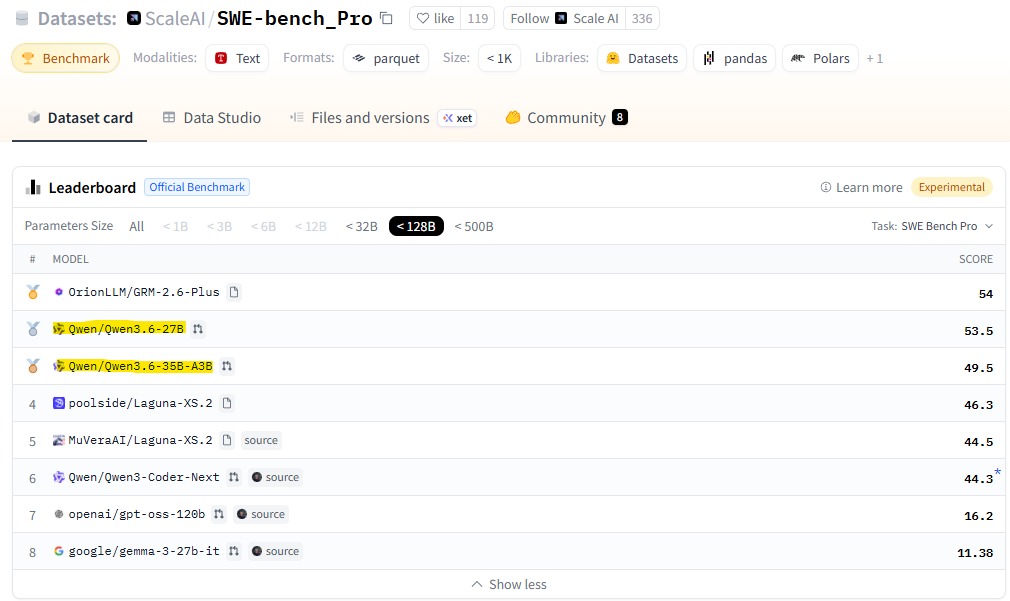
Если учесть, что OrionLLM/GRM-2.6-Plus это «файнтюн» Qwen, то хорошо видно:
- Лучше особо ничего нет, если меньше триллиона параметров
- А то, что есть, хорошо работает на отдельных машинах без всякой магии
Исходя из всего этого кластер было решено делать как интерфейс + прокси с автозагрузкой моделей по требованию + llama.cpp на воркерах. По крайней мере до следующего скачка в открытых моделях 70-128B, когда появится потребность или экономить память, или ускорять вычисления.
Но просто так делать было бы не интересно, поэтому делать было поручено агентам. За несколько вечеров результат достигнут. Кластер настроен. Методологию разберем отдельно, а тут обратная связь по моделям:
- Первые требования сделал очень крупные по размеру. Делал на Radeon AI PRO R9700 + qwen3.6-27b:UD-Q4_K_XL с кэшем в Q8_0. Очень даже неплохо получилось. Dense модель может в комплексные проекты. Но относительно медленно. MTP вне кода часто почти не помогает. Скорость падает до «терпимой», хотелось быстрее.
- Далее перешёл к более детальным требованиям и qwen3.6-35b-a3b:UD-Q8_K_XL на Ryzen 395. Вполне нормально работает. Токенов 50-60 с MTP есть, но на интерпретации запроса явно подтупливает, т. е. prefill не самая сильная сторона этого железа из-за скорости памяти. Надо понимать, что тот-же облачный квен не особо шустрее.
- Под конец перешел на qwen3.6-35b-a3b:UD-Q4_K_XL на Radeon AI PRO R9700. И, как ни странно, качества и скорости более чем достаточно. Работа почти интерактивная, качества хватает.
Ключевой вывод — для продуктивной работы вполне достаточно 4-битного кванта MoE модели.
И это очень классно.