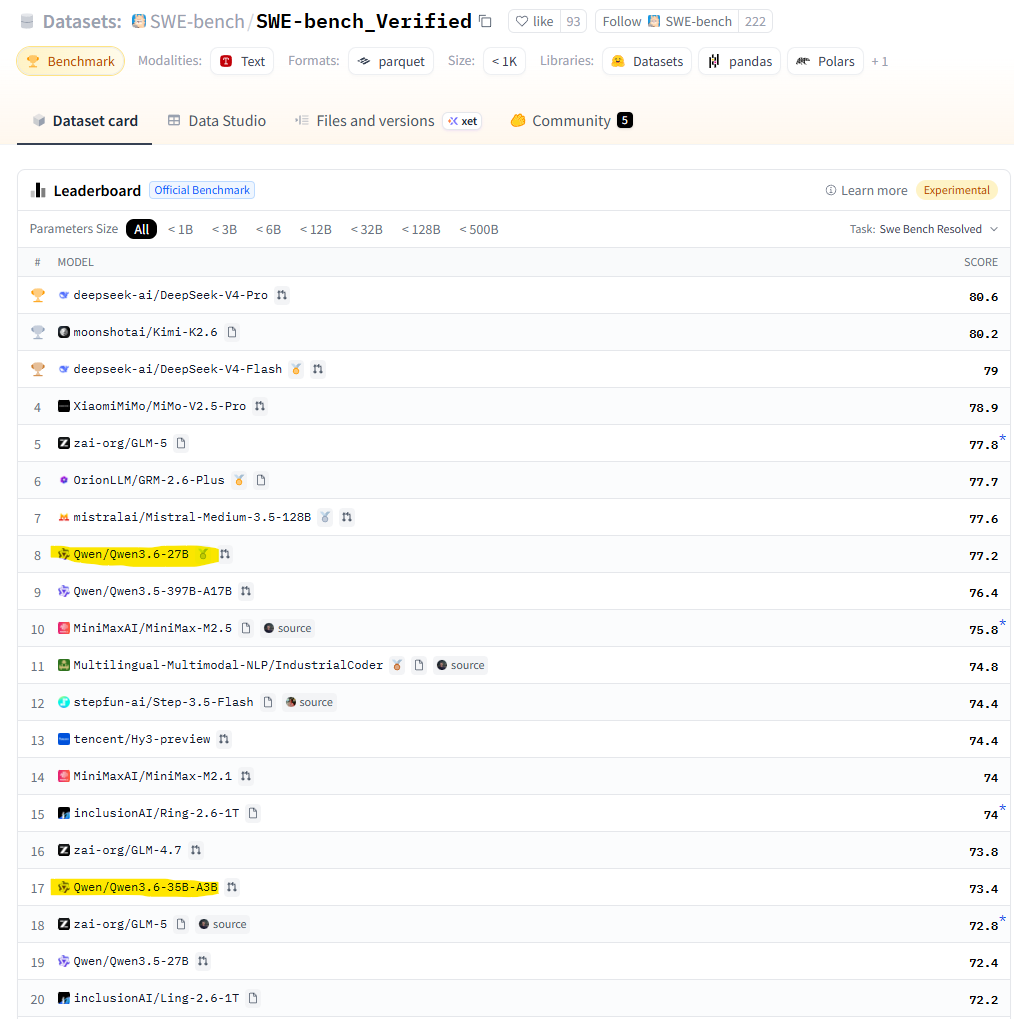
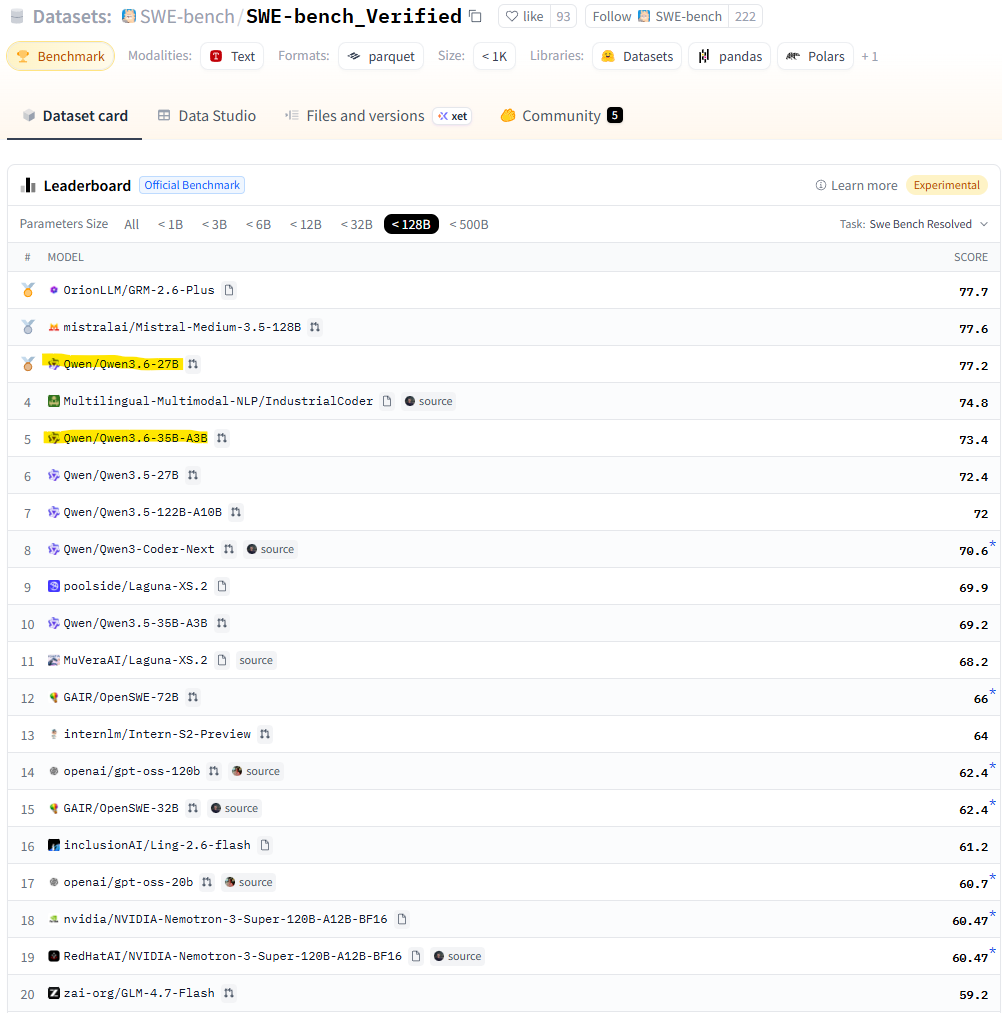
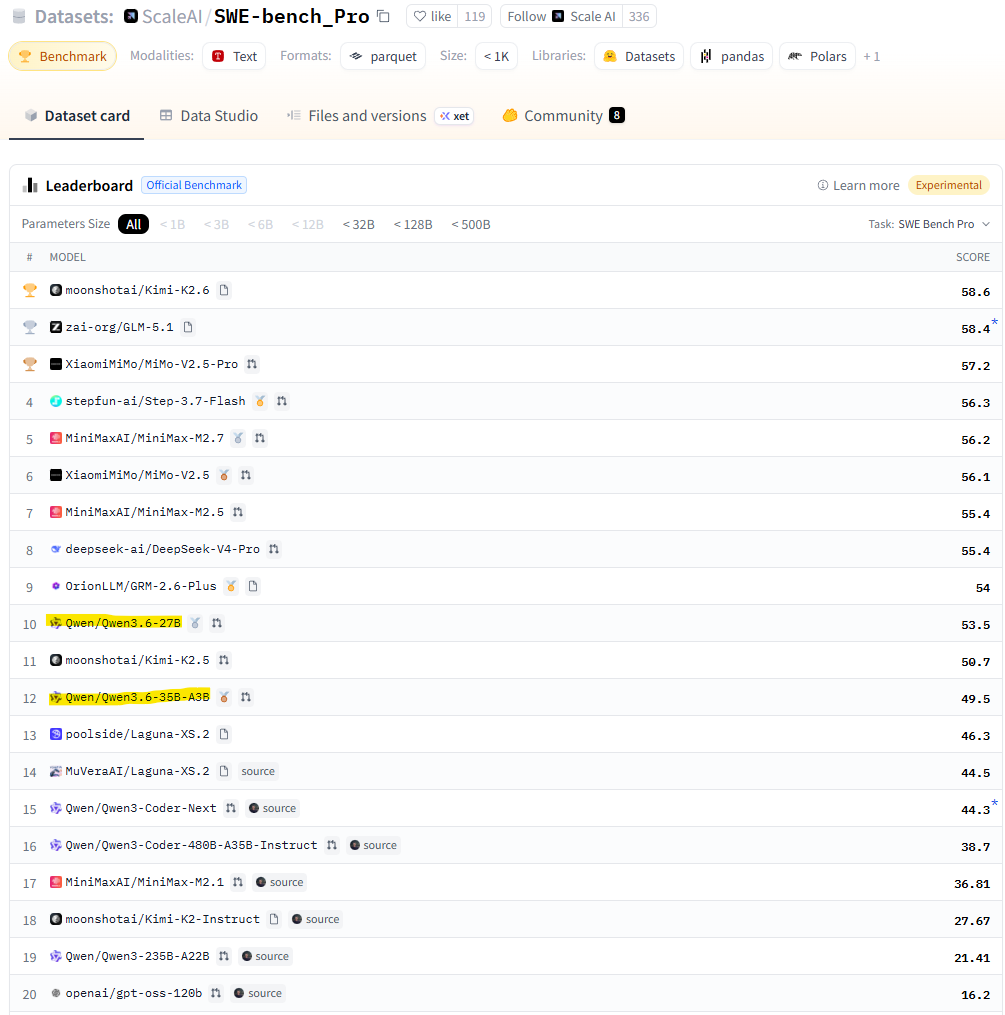
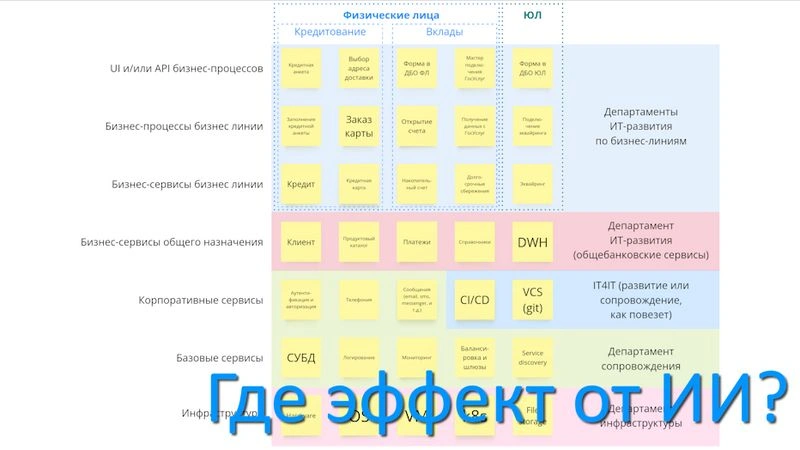
Сегодня нет ничего важнее ветра перемен.
В связи с тем, что популярные в наших широтах мессенджеры отказываются сотрудничать с Российской Федерацией и выполнять требования российского законодательства, настал момент навести немного порядка в публичную деятельность.
1) Основным каналом для общения с ув. подписчиками становится данная площадка на Sponsr.ru.
2) Кроме платных постов, здесь так же будут размещаться открытые рабочие заметки по тематике проекта, аналогично тому, что было в мессенджерах. Т.к. это просто дневник происходящего в жизни автора, то регламентировать график здесь не приходится.
3) В мессенджерах, пока это возможно с точки зрения законодательства, будут репосты.
4) По выходным планируется регулярно размещение платных постов с размышлениями и/или дневником сделанного за неделю по теме ИИ.
Сегодня нет ничего важнее ветра перемен.
В связи с тем, что популярные в наших широтах мессенджеры отказываются сотрудничать с Российской Федерацией и выполнять требования российского законодательства, настал момент навести немного порядка в публичную деятельность.
1) Основным каналом для общения с ув. подписчиками становится данная площадка на Sponsr.ru.
2) Кроме платных постов, здесь так же будут размещаться открытые рабочие заметки по тематике проекта, аналогично тому, что было в мессенджерах. Т.к. это просто дневник происходящего в жизни автора, то регламентировать график здесь не приходится.
3) В мессенджерах, пока это возможно с точки зрения законодательства, будут репосты.
4) По выходным планируется регулярно размещение платных постов с размышлениями и/или дневником сделанного за неделю по теме ИИ.